o4-mini and Gemini 2.5 Pro Can Ace Aider's Polyglot Benchmark
what does it mean when a model can score 95%+ on aider's polyglot benchmark? how does it change what you can do with it vs the 70% gemini pro is at now?
— jayk56.bsky.social (@jayk56.bsky.social) May 4, 2025 at 5:14 PM
This question has been hounding me this week…by my estimates the saturation of the latest programming benchmarks was coming as soon as the end of the year, but I stumbled onto something that makes me think we may already be there. The models can score 90+% with a small change in how the benchmark runs.
First, an important note on benchmarks:
This is a lesson I had to re-learn this week when I attempted to replicate the Aider benchmarks. I was excited to try it with the incredibly cheap Gemini Pro and answer some other ‘odd’ test cases the website doesn’t cover. Aider’s polygo is a programming specific benchmark, created at the end of 2024 due to the rapid progress that models have been making in code writing/editing. You can read more about how it was constucted on aider’s site: The polyglot benchmark
Here are the current top (single model) results for the Aider leaderboard:
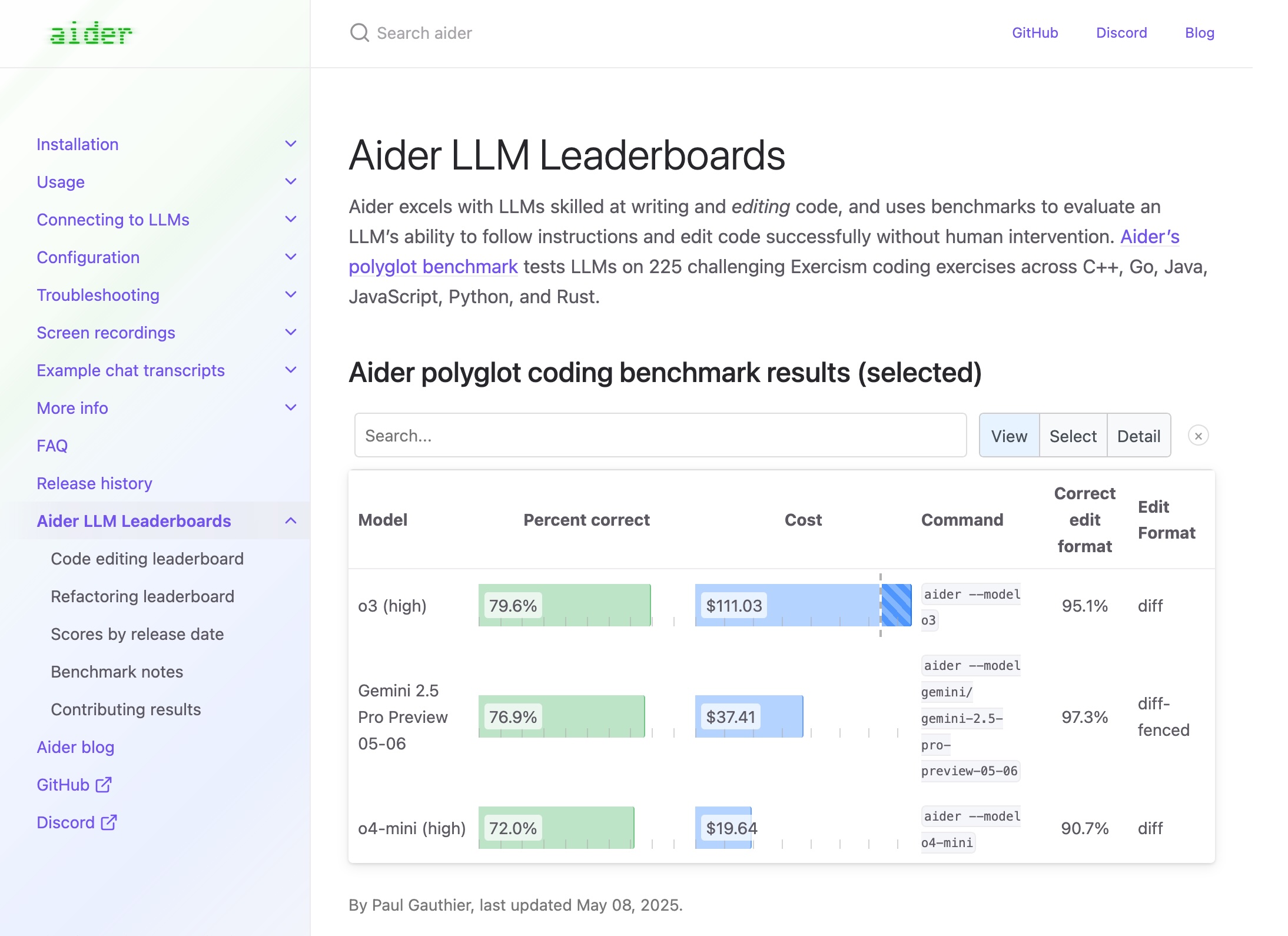
When you see this report of scores between 70% and 80% for the top models and may think:
- The mini does pretty good for its price!
- o3 is way too expensive!
- When you run the models against the 225 practice problems, they’ll get 70-80% of them right on the first try
This was my thinking, but that’s not quite what the leaderboard is showing. Here is the chart showing what was just described with the caveat I don’t have price information for only allowing 1 try and was only able to get the pass_1_rate from the site:
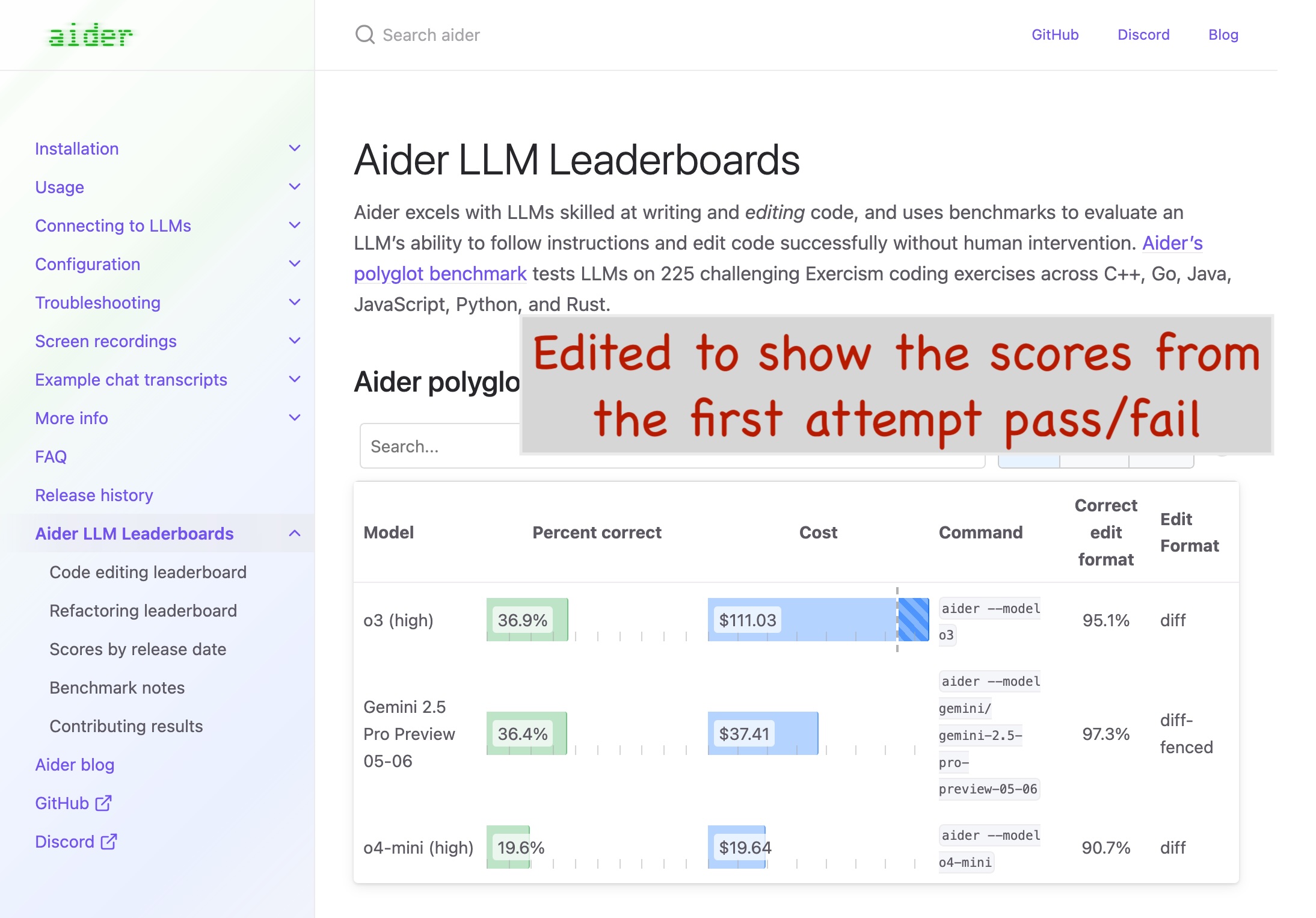
The original graph is showing the pass rate when the models have 2 attempts. Each models is given a chance to correct any mistakes after their first attempt at passing the unit tests. They are given information about what tests failed and what the error logs were and then they are asked to resolve the remaining issues. If the model fails on this second pass the benchmark counts it as a failure. Fair enough, with this new knowledge though, you may also notice a sharp rise in performance when you go from 1 try to 2 tries and wonder:
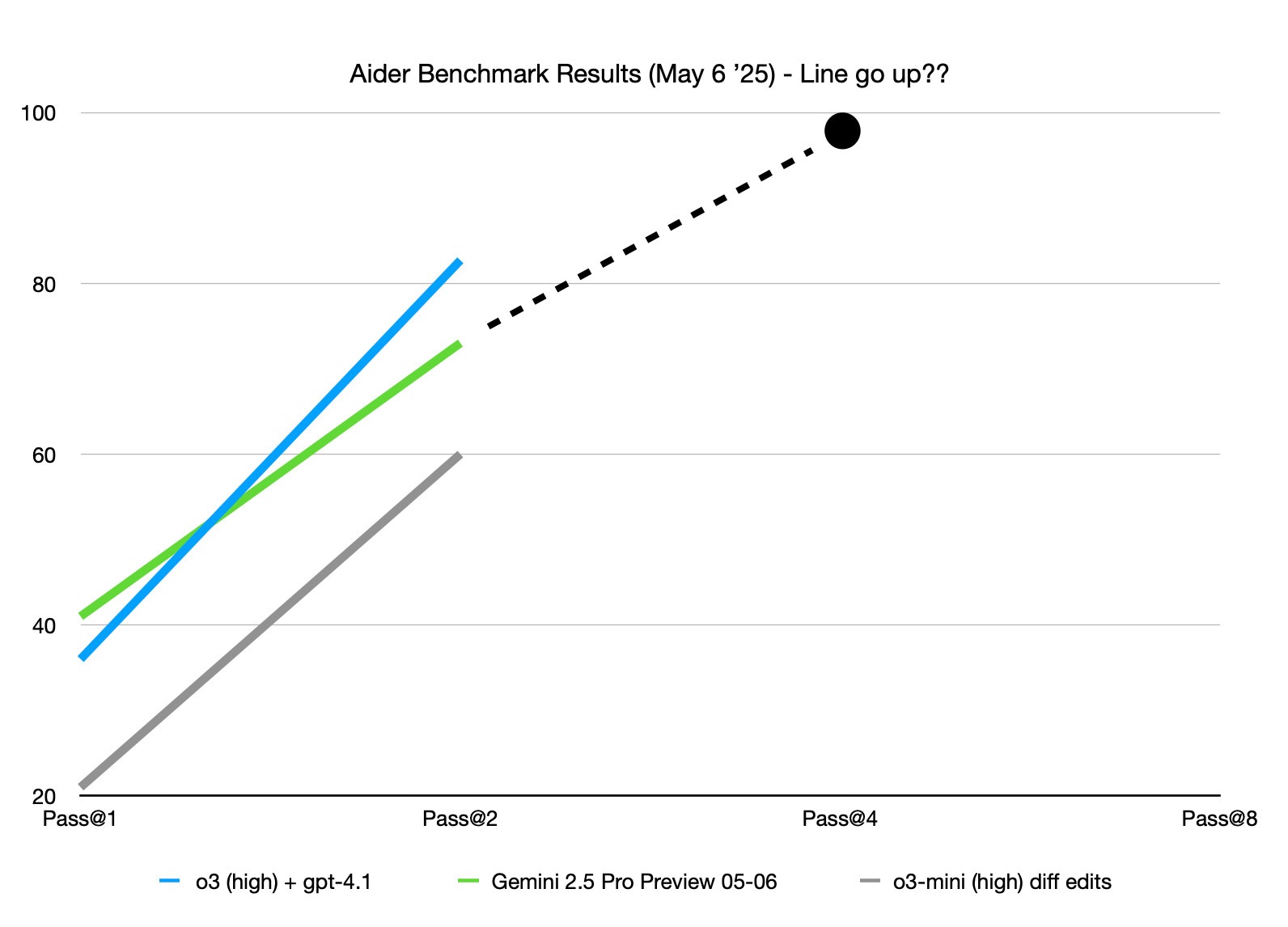
To which the answer is…
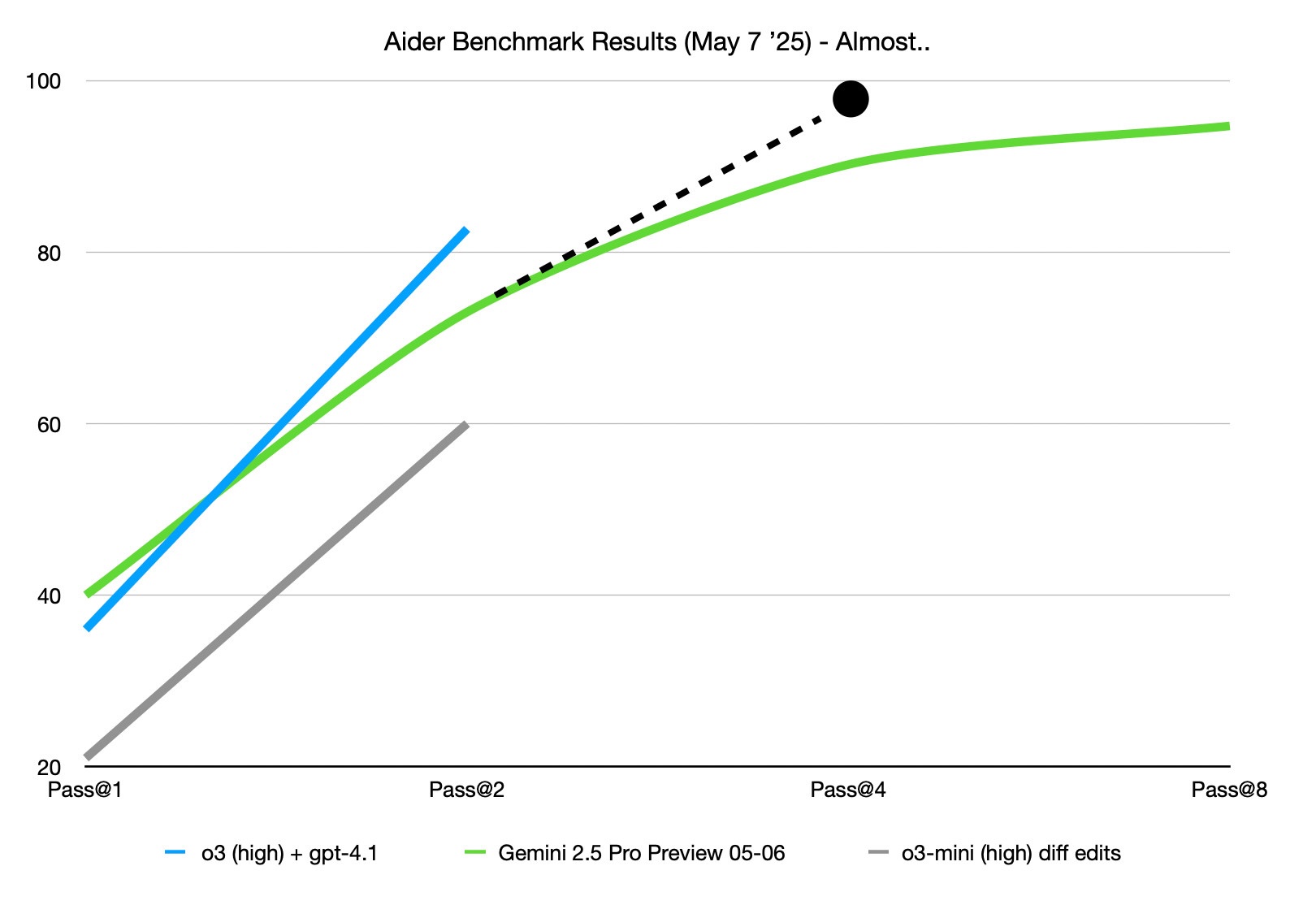
Almost..it follows a sub-linear power of x scaling which is pretty common in the recent ’test-time compute’ research where scaling the amount of tokens/thinking time/iterations provide large gains, but require exponentially more to get the last few % of possible improvement.
While the models don’t quite get perfect scores, it does show that they can get the right answers if given enough time. The economical models of today can score 90-95% if you give them more than 2 tries, while the top of the line models (the same for Gemini) can only get 37% correct on the first try. I think we can expect the next round of models (September-October) to cross into 98% territory with multiple tries, or 50% on the first attempt which means for writing or editing self contained code solutions we’re at the point where the AI will be more efficient than writing the code yourself. This doesn’t apply along the dimesions of: long codebases, dependency management hell, or secure, performant, easy-to-maintain code (yet) but, today, o4-mini and Gemini 2.5 Pro give us a glimpse of a future where most programming tasks can be automated, freeing developers up for other things.
Which brings us back to the question of, “So what changes now that aider can score 95%?”. Over the past month since these models were released, I’ve noticed that I can hand off more and more tasks to Github’s Copilot, and things just work! Whereas, before I had to wrangle context, specify the details of the change in detail and ensure to clean up any out of place code to avoid bad context tripping them up. Now, I can say ‘The exclamation icon on the left side seems a little off, can you improve the style of the alerts blocks?’ and 95% of the time can get what I want on the 2nd or 3rd try.
Claims of software development agents coming in the second half of 2025 sound more reasonable to me today than they did a month ago. If the major labs can crack 2 or 3 more roadblocks I have no problems imagining a world where for $2-4k a month (per agent) you could have
- a coder agent going to work on tasks for you with increasing precision
- a project management agent digesting user requirements, helping create, plan, and track software iterations
- a small team that keeps the agents on the rails and aligned with the business.
I don’t see the future where we don’t have any work, at least not before 2032, but I am excited to see what new software gets built now that it ‘can’.
Footnote: I got a bunch of interesting data from this experiment that I’m still sifting through. If you’re interested in following along, you can subscribe to my RSS feed here: rss feed, or follow me on bluesky where I’ll be posting some more graphics and links. If you’re interested in working on similar experiments but aren’t sure where to start, get in touch! I have more ideas than time and would love to talk through the details with others that are interested.
Attributions:
The text content is mine, with ’editorial review’ by Claude Sonnet 3.7
Screen grabs of Aider’s Leaderboard were captured from Aider LLM Leaderboards, and I used the official Aider repository for its benchmark harness to replicate/extend the analysis.
Alt text for images generated by GPT-4o in the ChatGPT app.